Introduction
An overview of the various eyetracker experiments conducted at Edinburgh University during the JAST project
Contents
- Eyetracking for two-person tasks with manipulation of a virtual world
- Data capture
- The experimental paradigm
- The experimental software (JCT)
- Experiment replay videos
- Interpreting participant behaviour
- Export to data display and analysis packages
- The experiments
Eyetracking for two-person tasks with manipulation of a virtual world
Eyetracking is an invaluable method that psychologists use to study reading, language processing, and visual attention. Although eyetracking hardware is robust and in widespread use, current software only supports knowing when participants are looking at predefined, static regions of the screen, and not what participants are attending to as they prepare to respond in a continuously changing context. While this limitation simplifies data collection and analysis, it encourages us to underestimate the real complexity of changing situations in which people actually observe, decide, and act. At present, we simply do not know how people handle multiple sources of external information, or multiple communication modalities. Despite growing interest in the interactive processes involved in human dialogue, the interaction between language and visual perception, how visual attention is directed by participants in collaborative tasks and the use of eye movements to investigate problem solving, the generation of such a rich, multimodal dataset has hitherto not been possible.
Given two eyetrackers and two screens, four breakthroughs are required before eyetracking can be used to study cooperation and attention in joint tasks. First, one central virtual world or game must drive both participants’ screens, so that both can see and manipulate objects in the same world. Second, it must be possible to record whether participants are looking at moving screen objects. Third, it must be possible for each participant to see indications of the other’s intentions, as they might in real face-to-face behavior. Here those intentions would be indicated by icons representing their partner’s gaze and mouse icons. Finally, to give a full account of the interactions between players, the eyetracking, speech, and game records of the two participants must be synchronized so that they run to the same time course for analysis. Finding solutions to these problems would open up eyetracking methodology not just to studies of joint action but to studies in other areas that require any of these four advances.
The JAST Eyetracking experiments developed solutions to all four problems, in the context of an experimental paradigm in which two participants jointly construct a figure that matches a given model. The experiments are described briefly below. The software used to runs the experiments, and the corpora generated by them, are available on this site.
Data capture
Dual eyetracking could be implemented using any pair of head-free or head-mounted eyetrackers as long as they will pass messages to each other. Our own implementation demonstrates it using two head-mounted Eyelink II eyetrackers. As supplied, each Eyelink II eyetracker comes with two computers connected via a local network. The host machine drives the eyetracking hardware by running the data capture and calibration routines, and the display machine runs the experimental software.
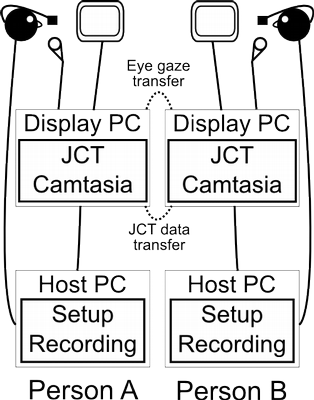
Our arrangement for dual eyetracking is shown schematically in the figure above. Here, because there are two eyetrackers, there are four computers. In addition to running the experimental software, the display machines perform audio and screen capture using TechSmith's Camtasia software and lapel microphones. Audio capture is needed if we are to analyse participant speech; screen capture provides some insurance against failure in the rest of the data recording by at least yielding a data version that can easily be inspected, although the resulting videos have no role in our data analysis.
As usual, the display machines are networked to their respective hosts so that they can control data recording and insert messages into the output data stream, but in addition, the display machines pass messages to each other. These are used to keep the displays synchronized; for instance, if a participant moves his eyes, his mouse, or some on-screen object, the experimental software running on their display machine will send a message to that effect to the experimental software on the other, which will then update the graphics to show the gaze cursor, mouse cursor, or object in its new location. Coordinating the game state is simply a matter of passing sufficient messages.
The figure below shows a photograph of our experimental apparatus set up in our eyetracker lab.

The experimental paradigm
In our experimental paradigm, two participants play a series of construction games. Their task is to reproduce a static two-dimensional model by selecting the correct parts from an adequate set and joining them correctly. Either participant can select and move or rotate any part. Two parts will be joined together permanently if each participant holds one and they make the two touch. The resulting composite can be broken deliberately if it is incorrect, and new parts can be drawn from templates as required. Parts break if both participants select them at the same time, if they are moved out of the model construction area, or if they bump into an unselected part. The following figure shows an annotated version of the participant display from our implementation of the paradigm that labels the cursors and static screen regions. It has a model at the top right with the initial parts underneath it, a broken part counter at the top left, a timer in the middle at the top, and new part templates across the bottom of the screen. After each trial, the participants can be shown a score reflecting accuracy of their figure against the given model.
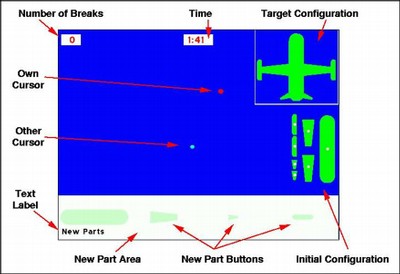
This experimental paradigm is designed to provide a joint task that can only be completed by collaborating. The general framework admits a number of independent variables, such as the complexity of the model, the difficulty of constructing it given how the initial parts are packed, and whether or not the participants have access to each other’s speech, gaze cursor, or mouse position. The paradigm is suitable for a range of research interests in the area of joint activity. Performance can be measured in terms of time taken, breakages, and accuracy of the constructed figure against the target model, for which we use the maximum percentage of pixels that are colored correctly when the constructed figure is laid over the model and rotated. In addition, the paradigm allows for an analogous task for individuals that serves a useful control. In the individual task, two parts join together when they touch, even if only one is selected.
The experimental software (JCT)
The Jast Construction Task, or JCT, is software for running experiments that fit this experimental paradigm. It is implemented under Windows XP in Microsoft Visual C++.Net and draws on a number of open source software libraries.
The configuration of an experiment is defined by a set of XML files. Each experiment consists of a number of trials using one model per trial. The initial and target configuration for each model, and descriptions of the polygon parts used, is stored in a "Stimulus Set" XML file, and the experiment configuration links to a number of these files which are presented in order.
In this implementation of the experimental paradigm, the messages passed between the eyetrackers, and therefore stored in the output, are:
- markers showing the time when each trial started and end, along with the performance scores by trial for accuracy and number of breakages;
- markers near the beginnings of trials showing when a special audio tone and graphical symbol were displayed, to make it easier to synchronize the data against audio and video recordings;
- participant eye positions;
- sufficient information to reconstruct the model-building state, including joins, breakages, part creation, and any changes in the locations or rotations of individual parts.
Experiment replay videos
Our first step after data capture is to use the ASCII eyetracker outputs to create videos that replay the experiments conducted. Although we could simply rely on screen capture for this, reconstructing the videos from the data has a number of advantages. First, should there be any problems with the data recording in the experimental software, they will be much more obvious from inspecting the reconstructed video than from the data files themselves. During software development, we used experiment replay as a debugging tool. Second, since we have access to complete information about the eye and mouse positions from both participants, we can create videos that show more than what the participants themselves saw. It is probably never useful for participants to see their own eye traces during experiments, and for some experiments, they should not see their partner’s eye trace or mouse either. Analysts, on the other hand, usually want to see everything.
Our video reconstruction utility takes the ASCII data from one of the eyetrackers and uses it to create a video that shows the task with the eye and mouse positions of the two participants superimposed. The videos produced from the two ASCII data files for the same experiment are the same apart from subtle differences in timing: each video shows the data at the time that it arrived at, or was produced by, the individual eyetracker used as its source. The utility, which is again written in Microsoft Visual C++.Net, uses FFMPEG and libraries from the JCT experimental software to produce MPEG2 format videos with a choice of screen resolutions and colour depths.
Interpreting participant behaviour
The act of capturing the data using the methods described creates a record that completely describes what happened during the experiment, but using primitives below what is required for analysis. For instance, the messages describe the absolute positions of eyes, mice, and all parts throughout the task, but not in terms of when a participant is looking at a particular part, even though knowing this is essential to understanding how gaze, speech, and action relate. Therefore, the next step is to add this higher level of analysis to the data set. At the same time, we transfer the data out of the ASCII format exported by the Eyelink II and into an XML format. This is because using XML means we do not have to write our own parser for our data format, and because XML makes it easy to check that the data conforms to our expectations, by validating data files against a document type definition describing what they should contain.
The resulting XML file contains most of the information gathered so far in the experiment. Drawing data from the output of both eyetrackers and from the experiment configuration file, it includes all of the messages that were passed, parsed eye data for both participants, plus a list of the parts, their movements and their join events, with part properties, such as shape and initial locations, taken from the experiment configuration file.
In addition to re-encoding these kinds of data from the experimental software, the utility that produces the XML file adds the following data interpretations:
- "look" events during which a participant looked at a part, composite, or static region. These events cover the entire time that the eye position is within a configurable distance of the moving screen region associated with whatever is being looked at, whether the eye is currently engaged in a fixation or a saccade. Since the XML data contains parsed eye movements, the difference can be established in later analysis, if required.
- "hover" events during which a participant hovered the mouse over a part or composite, again defined as covering the entire time that the mouse cursor is within a configurable distance of the moving screen region associated with the part.
- for each trial, a description of how the pair constructed the figure, given as a set of binary tree where the leaves are the parts and each node shows a composite created by joining the composites or parts that are the children of the node.
- for each creation of a composite, a division into construction phases from the first move to the final join, useful for task analysis. The phases used divide out the final action of docking the last piece of the composite and otherwise simply divide the rest of the time spent in half.
- per-trial breakage scores calculated over the GDF format for use as a parity check against those coming directly from the experimental software.
The "JastAnalyzer" software that performs this processing requires the same environment as the JCT experimental software. It works by passing the ASCII data back through libraries from the JCT software in order to interpret the task state. Because we use the resulting XML data set for a number of different purposes, we call this data format our "General Data Format", or GDF. It is straightforward, given the data format, to produce scripts that show useful analyses, such as the lag between when one participant looks at an object and the other participant follows. It is also easy to produce per-trial summary statistics, such as how many times a participant looked at each of the parts and what percentage of the time they spent looking at the clock.
Export to data display and analysis packages
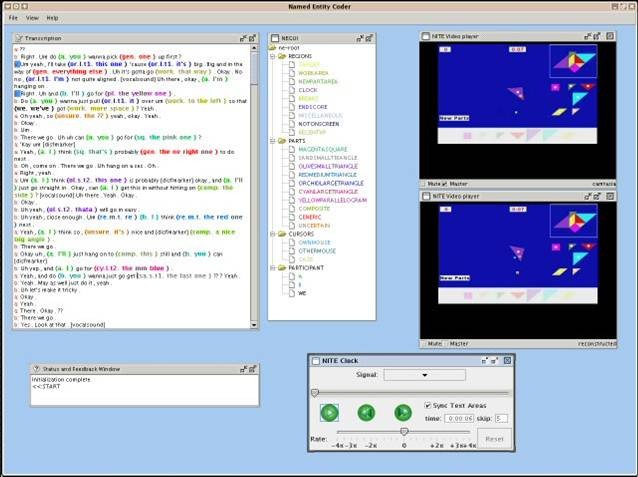
For more complicated data analysis, we export from our General Data Format into the format for existing data display and analysis packages that allow the data to be inspected graphically, "playing" it synchronized to the video and audio records. Such packages are useful both for checking that the data is as expected and for browsing it with an eye to understanding participant behaviour. However, their real strength is that they can be used to create or import other sources of information for the same data, such as orthographic transcription, linguistic annotations relating to discourse phenomena, and video coding. Some such packages also provide data search facilities that can be used to conduct analyses beyond the simple ones that our GDF-based scripts produce, including ones involving the relationship between task behaviour and speech. In our software, we include export to two such packages, ELAN and the NITE XML Toolkit (NXT). Both can show behavioral data in synchrony with one or more corresponding audio and video signals, and have support for some kinds of additional data annotation. ELAN has strengths in displaying the time course of annotations that can be represented as tiers of mutually exclusive, timestamped codes, whereas NXT has strengths in supporting the creation and search of annotations that relate to each other both temporally and structurally, as is usual for linguistic annotations built on top of orthographic transcription.
An example screenshot of NXT running on the JAST corpora data is shown below.
The experiments
A set of three experiments was conducted by the Edinburgh group during the JAST project. These all used target models based upon tangram pieces; an example is shown in the following picture.

A brief description of each of the three Edinburgh JAST corpora, JCTE1, JCTE2 and JCTE3, is presented in the following subsections.
I. JCTE Corpus 1
Summary
JCTE 1 involves two participants each connected to their own eye-tracker but working within a shared virtual environment. Participants had to adhere to a strict set of rules which ensured that both participants had to take an active part in the construction process. The data from 32 dyads have been collated across four Independent Variables:
- Within subjects
- With or without spoken dialogue
- With or without gaze feedback (the projection of the interlocutor’s gaze on the screen enabling each member of the dyad to know directly where the other person is looking)
- Between subjects
- Role assignment where either a dyad is explicitly formed with a manager and assistant, or dyads are free to spontaneously develop their own working relationship.
- The dyad could verbally communicate during only either the first half of the experiment or the second half.
Materials and Design
16 innominate (i.e. they could not be obviously identified or named as something) 7-part tangrams were constructed from an exhaustive set of seven "standard" tangram parts. The same set of two large triangles, two small triangles, one medium triangle, one square and one parallelogram was available in each construction trial. Each of the seven parts had a different colour. Below is the whole experimental item matrix.
| Subject Pair | Block Order | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Block 1 | Block 2 | Block 3 | Block 4 | ||||||
| Free | Assign | Cond | Item | Cond | Item | Cond | Item | Cond | Item |
| 1 | 9 | A | a | B | b | C | c | D | d |
| 2 | 10 | B | c | A | d | D | a | C | b |
| 3 | 11 | A | b | B | a | D | d | C | c |
| 4 | 12 | B | d | A | c | C | b | D | a |
| 5 | 13 | C | a | D | b | A | c | B | d |
| 6 | 14 | D | c | C | d | B | a | A | b |
| 7 | 15 | D | b | C | a | A | d | B | c |
| 8 | 16 | C | d | D | c | B | b | A | a |
| 17 | 25 | A | d | B | c | C | b | D | a |
| 18 | 26 | B | b | A | a | D | d | C | c |
| 19 | 27 | A | c | B | d | D | a | C | b |
| 20 | 28 | B | a | A | b | C | c | D | d |
| 21 | 29 | C | d | D | c | A | b | B | a |
| 22 | 30 | D | b | C | a | B | d | A | c |
| 23 | 31 | D | a | C | d | A | a | B | b |
| 24 | 32 | C | c | D | b | B | c | A | d |
Cell Legend:
|
|
|
|||||||||||||||||||||||||||||
II. JCTE Corpus 2
Summary
The design and procedure were similar to JCTE 1, only there was an additional within subjects variable: the visibility of the other person’s mouse cursor was also manipulated, with the cursor only visible in half the trials. The data from 32 dyads have been collated across four Independent Variables:
- Between subjects
- Role Assignment (Free or Assigned)
- Speech Order (Block: speech permitted in first or second half of experiment)
- Within subjects
- Linguistic Communication (Speech or No Speech)
- Gaze Feedback (Yes or No)
- Mouse Feedback (Yes or No)
Materials and Design
Again there were 16 models but of a more complex variety. Models were counterbalanced across the eight condition combinations with two trials per condition cell. There were also four different layouts of the initial parts counterbalanced across experimental items. The same set of initial parts was available at the beginning of each trial and these were based on a standard seven-piece tangram. Each of the standard seven pieces were coloured differently but there were doubles of all the pieces except for the parallelogram, making an initial array of 13 parts in total; this prevented unique reference to parts being made by colour or shape alone. The target models were constructed from 11 of these component parts, leaving two redundant pieces in each trial. The redundant pieces differed from trial to trial. Additionally, two parts of each model was designed to look as if they were a single component but were actually subassemblies (e.g. a green parallelogram was actually two green triangles joined together). The models themselves all formed abstract shapes rather than identifiable or nameable objects.
| Block Order | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dyad | Role | Part 1 | Part 2 | ||||||||||||||
| Block 9 | Block 2 | Block 3 | Block 4 | Block 5 | Block 6 | Block 7 | Block 8 | ||||||||||
| Cond | Item | Cond | Item | Cond | Item | Cond | Item | Cond | Item | Cond | Item | Cond | Item | Cond | Item | ||
| 1 | 0 | A | a | B | b | D | c | C | h | E | g | F | d | G | f | H | e |
| 2 | 0 | B | c | C | a | A | b | D | d | F | e | G | g | H | f | E | h |
| 3 | 0 | C | b | D | e | B | d | A | c | H | g | E | a | F | f | G | h |
| 4 | 0 | D | f | A | d | C | c | B | e | G | a | H | h | E | b | F | g |
| 5 | 0 | E | c | F | h | H | a | G | b | A | e | B | f | C | d | D | g |
| 6 | 0 | F | a | G | c | E | d | H | b | B | g | C | e | D | h | A | f |
| 7 | 0 | G | d | H | c | F | b | E | e | D | a | A | g | B | h | C | f |
| 8 | 0 | H | d | E | f | G | e | F | c | C | g | D | b | A | h | B | a |
| 9 | 0 | C | e | D | h | A | f | B | g | F | a | G | c | E | d | H | b |
| 10 | 0 | A | g | B | h | C | f | D | a | G | d | H | c | F | b | E | e |
| 11 | 0 | B | a | C | g | D | b | A | h | H | d | E | f | G | e | F | c |
| 12 | 0 | D | g | A | e | B | f | C | d | E | c | F | h | H | a | G | b |
| 13 | 0 | H | e | E | g | F | d | G | f | A | a | B | b | D | c | C | h |
| 14 | 0 | G | g | H | f | E | h | F | e | B | c | C | a | A | b | D | d |
| 15 | 0 | E | a | F | f | G | h | H | g | C | b | D | e | B | d | A | c |
| 16 | 0 | F | g | G | a | H | h | E | b | D | f | A | d | C | c | B | e |
| 17 | 1 | A | a | B | b | D | c | C | h | F | d | G | f | H | e | E | g |
| 18 | 1 | B | c | C | a | A | b | D | d | H | f | E | h | F | e | G | g |
| 19 | 1 | C | b | D | e | B | d | A | c | G | h | H | g | E | a | F | f |
| 20 | 1 | D | f | A | d | C | c | B | e | E | b | F | g | G | a | H | h |
| 21 | 1 | E | c | F | h | H | a | G | b | B | f | C | d | D | g | A | e |
| 22 | 1 | F | a | G | c | E | d | H | b | D | h | A | f | B | g | C | e |
| 23 | 1 | G | d | H | c | F | b | E | e | C | f | D | a | A | g | B | h |
| 24 | 1 | H | d | E | f | G | e | F | c | A | h | B | a | C | g | D | b |
| 25 | 1 | A | f | B | g | C | e | D | h | F | a | G | c | E | d | H | b |
| 26 | 1 | B | h | C | f | D | a | A | g | G | d | H | c | F | b | E | e |
| 27 | 1 | D | b | A | h | B | a | C | g | H | d | E | f | G | e | F | c |
| 28 | 1 | C | d | D | g | A | e | B | f | E | c | F | h | H | a | G | b |
| 29 | 1 | G | f | H | e | E | g | F | d | A | a | B | b | D | c | C | h |
| 30 | 1 | E | h | F | e | G | g | H | f | B | c | C | a | A | b | D | d |
| 31 | 1 | F | f | G | h | H | g | E | a | C | b | D | e | B | d | A | c |
| 32 | 1 | H | h | E | b | F | g | G | a | D | f | A | d | C | c | B | e |
Cell Legend:
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Corpora contrasts
The primary differences in the task that necessitate greater planning and strategic development in Corpus 2 over Corpus 1 are:
-
an increase in the number of parts in each model result in more elaborate constructs, an increase in the number of possible (valid) actions, longer completion times, as well as potentially higher rebuild costs when mistakes are made;
-
doubles of six of the seven pieces prevent unique reference to parts;
-
each model contains two instances of geometric components that are actually sub-assemblies made from two smaller parts where the joining edges are not obvious from the displayed model (e.g. a green parallelogram must be seamlessly created from two green triangles);
-
two pieces (differing for each model) that are provided in the initial set of parts are redundant;
-
greatly impoverished clues to intentionality in some trials (no speech, gaze position or mouse cursor).
III. JCTE Corpus 3
Summary
The design and procedure were similar to JCTE 1 and 2. We used the set of tangrams used in the Nijmegen experiment, which introduced tangrams in similar colour. We added the asymmetrical mouse-cross projection situation (i.e., only one participant's mouse is cross-projected on the other person's monitor) and Instruction Emphasis as our manipulation. Speech/No Speech manipulation is not included in this experiment. The data have been collated across the following Independent Variables:
- Within subjects
- Mouse Feedback
- Between subjects
- Role Assignment
- Instructions Emphasis
Mouse feedback was manipulated for each participant individually, which creates four conditions as below:
| Condition | ||||
|---|---|---|---|---|
| A | B | C | D | |
| A projected | 0 | 0 | 1 | 1 |
| B projected | 0 | 1 | 0 | 1 |
| ShowOtherCursor | -A, -B | +A, -B | -A, +B | +A, +B |
| SeeS | -A, -B | +A, -B | -A, +B | +A, +B |
| SeeN | -A, -B | -A, +B | +A, -B | +A, +B |
* + means visible and - invisible.
Another new variable added was Instruction Emphasis. Half of dyads saw the instruction before each trial emphasizing their own view ("you will/will not see the other person’s mouse cursor) whereas the other half were given the instruction emphasizing their partner's view ("The other person will see your mouse cursor").
Materials
We used the sixteen 7-part models that were used in the Nijmegen experiment, in which there are multiple objects in similar colours. Like the duplications in JCTE 2, this change was designed to encourage participants to produce referring expressions.
The whole experimental item matrix is shown below.
| Dyad | Block Order | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| No Role | Role | Block 1 | Block 2 | Block 3 | Block 4 | ||||||
| SeeS | SeeN | SeeS | SeeN | Cond | Item | Cond | Item | Cond | Item | Cond | Item |
| 1 | 9 | 17 | 25 | A | a | B | b | C | c | D | d |
| 2 | 10 | 18 | 26 | D | b | C | a | B | d | A | c |
| 3 | 11 | 19 | 27 | B | c | A | d | D | a | C | b |
| 4 | 12 | 20 | 28 | C | d | D | c | A | b | B | a |
| 5 | 13 | 21 | 29 | A | d | D | b | B | c | C | a |
| 6 | 14 | 22 | 30 | B | b | C | d | A | a | D | c |
| 7 | 15 | 23 | 31 | C | c | B | a | D | d | A | b |
| 8 | 16 | 24 | 32 | D | a | A | c | C | b | B | d |
Cell Legend:
|
|
|
JCTE 3 is based on the Nijmegen experiment, with the following deviations from their design:
- No time pressure.
- Gender proportions not necessarily matched.
- Cursor sizes kept the same as in the JCTE 1 and JCTE 2 experiments (larger than Nijmegen).
- Item order scrambled (Item order was always fixed (tangram 1 - 16) for their experiment).
- Participants always saw a reminder before each trial (In the Nijmegen experiment, only the SeeN experiment had a reminder message before each trial).